Zig, Parser Combinators - and Why They're Awesome
In this article we will be exploring what parser combinators are, what runtime parser generation is - why they’re useful, and then walking through a Zig implementation of them.
- What are parser combinators?
- Why are parser combinators useful?
- Going deeper: runtime parser generation
- A note about traditional regex engines
- Implementing the Parser interface
- Our first Parser
- Our first parser combinator
- Using our OneOf parser combinator
- Runtime parser generation
- Closing thoughts
What are parser combinators?
A parser parses some text to produce a result:

A parser combinator is a higher-order function which takes parsers as input and produces a new parser as output:

Why are parser combinators useful?
Let’s say we want to parse the syntax which describes a regular expression: a[bc].*abc
We can define some parsers to help us parse this syntax (e.g. into tokens or AST nodes):
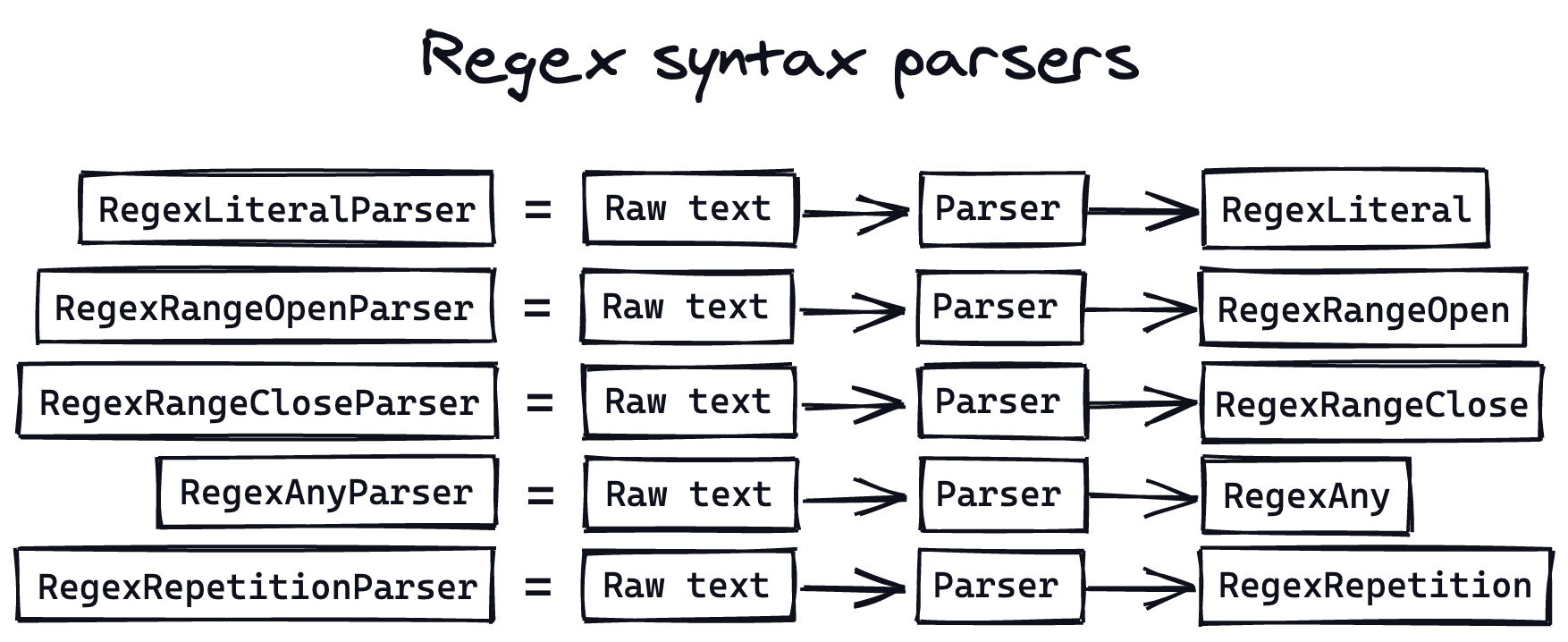
Suppose that for a[bc].*abc:
RegexLiteralParsercan parsea,b, andc, but notabc(the string.)RegexRangeOpenParsercan parse[.RegexRangeCloseParsercan parse]RegexAnyParsercan parse the.“any character” syntax.RegexRepetitionParsercan parse the*repetition operator.
Now that we have these parsers, we can define parser combinators to help us parse the full regular expression. First, we need something to parse a string abc which we can define as:
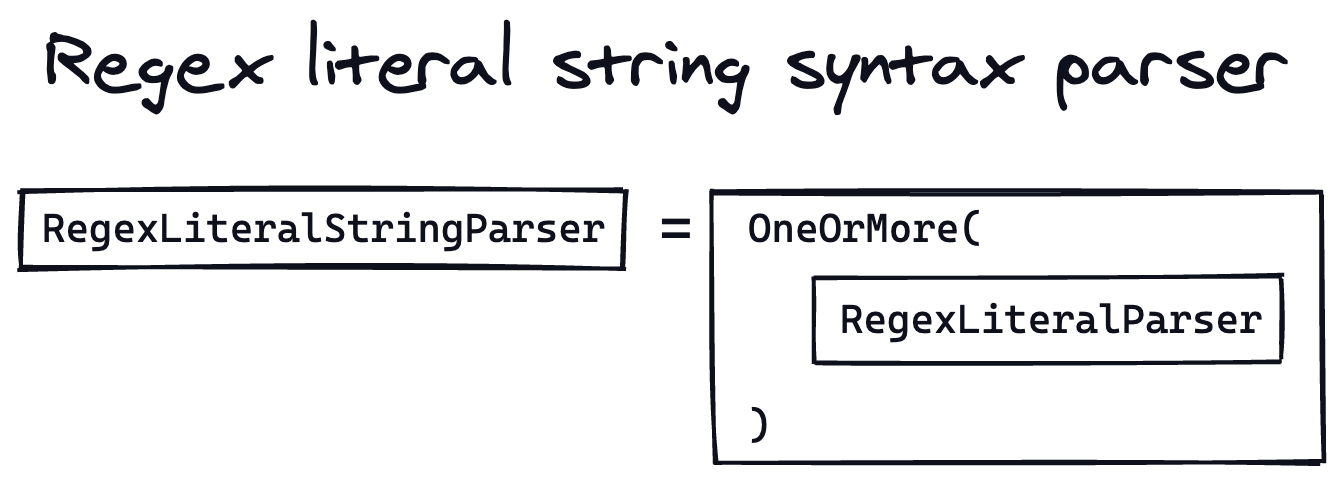
What is OneOrMore, though? That’s our first parser combinator!
It takes a single parser as input (in this case, RegexLiteralParser) and uses it to parse the input one or more times. If it succeeded once, the parser combinator succeeded. Otherwise, it failed to parse anything.
Now if we want to parse the [bc] part of our regex, let’s say it can only contain a literal like bc (of course, real regex allows far more than this) we can e.g. reuse our new RegexStringLiteralParser:

In this case, Sequence is a parser combinator which takes multiple parsers and tries to parse them one-after-the-other in order, requiring all to succeed or failing otherwise.
Building upon this basic idea, we can use parser combinators to build a full regex syntax parser:

Going deeper: runtime parser generation
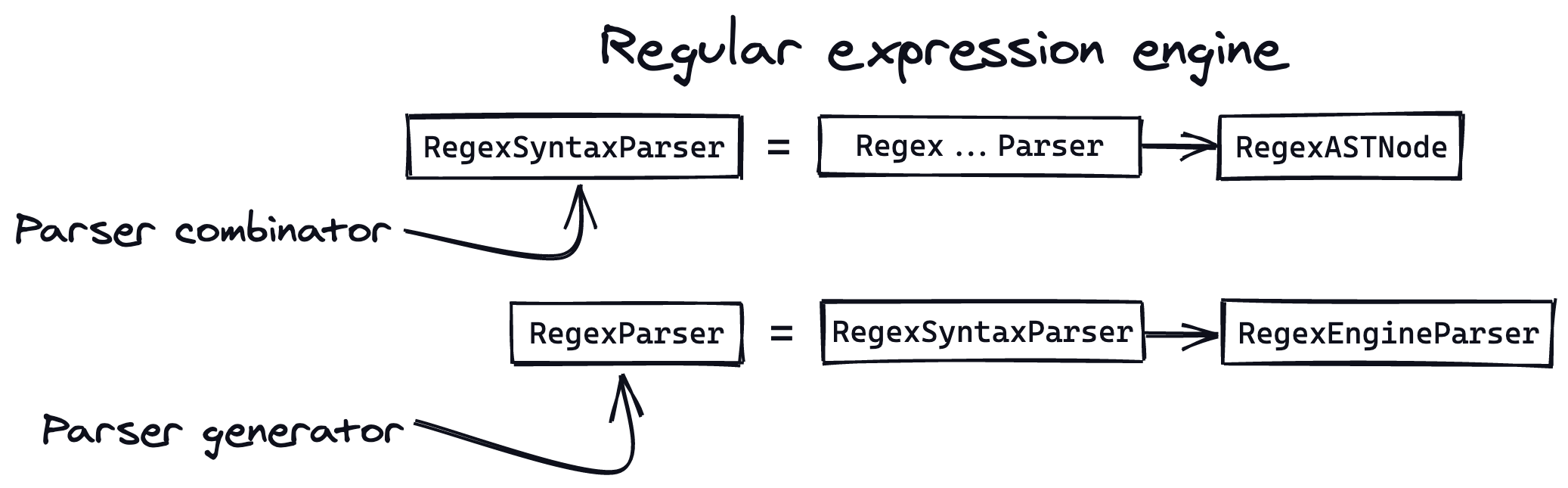
From before, our parser combinator RegexSyntaxParser is built out of multiple parsers (Regex...Parser) and ultimately produces an AST describing the syntax for a given regex.
We can use the same combinatorial principle here to introduce a new parser generator called RegexParser which uses RegexSyntaxParser to create a brand new parser at runtime that is capable of parsing the actual semantics the regex describes - forming a full regex engine:
A note about traditional regex engines
Revised Mar 10, 2021 to clarify a misunderstanding I had about about the difference between DFA and NFA regex engines. Thanks @burntsushi for helping me to learn!
Production grade regex engines are either finite automata based or backtracking based, and are described in great detail in Russ Cox’s article here and his second article here covering the virtual-machine approach commonly used in regex engines.
It’s worth noting that combinatorial parsing and generating parsers at runtime is very much an uncommon method of implementing a regular expression engine. This is somewhat close to what Comby does in practice, although we use a runtime parser generator instead of parser parser combinators.
One could argue this makes what we’re parsing not strictly regular expressions, although as Larry Wall (author of the Perl programming language) writes, neither are the modern “regexp” pattern matchers you are likely used to:
“Regular expressions” […] are only marginally related to real regular expressions. Nevertheless, the term has grown with the capabilities of our pattern matching engines, so I’m not going to try to fight linguistic necessity here. I will, however, generally call them “regexes” (or “regexen”, when I’m in an Anglo-Saxon mood).
Implementing the Parser interface
Parser combinators tend to be written in higher-level languages with much fancier type-systems such as Haskell and OCaml, which lend themselves well to higher-order functions like parser combinators.
We’ll be implementing this in Zig, which is a new low-level language aiming to be a better C.
Compile-time vs. run-time
Zig has very cool compile-time code execution semantics which help provide its generics. We’ll be exploring these a bit, but since we want to ultimately build parser generators at runtime (in order to execute a regexp) what we’ll be looking at is mostly runtime parser interfaces rather than compile-time parser interfaces (which are very much possible!)
Since we’ll be dealing with heap allocations, our parser will not be able to run at comptime for now. Once Zig gets comptime heap allocations this should be possible and opens up interesting new opportunities.
The parser interface
We need an interface in Zig which describes a parser as we previously mentioned:
Here it is - there’s a lot to unpack here so we’ll walk through it step-by-step:
pub fn Parser(comptime Value: type, comptime Reader: type) type {
return struct {
const Self = @This();
_parse: fn(self: *Self, allocator: *Allocator, src: *Reader) callconv(.Inline) Error!?Value,
pub fn parse(self: *Self, allocator: *Allocator, src: *Reader) callconv(.Inline) Error!?Value {
return self._parse(self, allocator, src);
}
};
}
Zig generics are provided via type parameters
pub fn Parser(comptime Value: type, comptime Reader: type) type {
return struct {
...
};
}
This is a Zig function which takes two arbitrary type arguments at comptime, named Value and Reader. Uppercase is used to denote the name of a type in Zig. Thes are:
Valuewill be the type of the actual value that the parser will produce (e.g. a string of matched text, or an AST note.)Readerwill be the type of the actual source of the raw text to parse (we’ll cover this more later.)
The function itself returns a new type.
What we’re seeing here is the key way in which Zig approaches generic data structures: you merely pass around types as parameters - as if they were values - and you write functions which take types as parameters and return types as values. Some examples of valid calls to this function are:
Parser(u8, []u8)whereu8is an unsigned 8-bit integer and[]u8is a slice of unsigned 8-bit integers.Parser([]const u8, @TypeOf(reader))where[]const u8is describing a slice of UTF-8 text (a string) andreaderis some reader type, such asstd.io.fixedBufferStream("foobar").
Zig runtime interfaces
Now, since we’re trying to define an interface whose actual implementation can be swapped out at runtime - what we need is pretty simple:
- A
structtype which has the methods we want every implementation to provide. - Those methods to call function pointers which are defined as fields of our struct.
Basically, if someone wants to implement our interface they just need to create a new instance of Parser and populate the fields (callbacks) so their implementation is called when the interface is used.
This is the same pattern used by the Zig std.mem.Allocator interface.
In our case here, the returned struct has a method that consumers of the interface would invoke called parse - and the function pointer field that implementors will set to get a callback is the _parse field:

Type parameters
Let’s look at some of the data types going around here:

A few other notes:
Error!?Valueis just describing the function can return anErrorOR no value OR aValuetype. See Zig’s error union types and optional types.callconv(.Inline)is just telling the compiler to inline the function call - since our function isn’t doing a ton.
Errors the Parser interface can produce
Our error type might start out looking something like this:
pub const Error = error{
EndOfStream,
} || std.mem.Allocator.Error;
error{...} describes a set of potential errors and || std.mem.Allocator.Error merely says to merge the allocator type’s error set with ours - so our potential set of errors includes ours and theirs.
As we start performing different operations within parsers, it will become more complex to describe more potential sources of errors:
pub const Error = error{
EndOfStream,
Utf8InvalidStartByte,
} || std.fs.File.ReadError
|| std.fs.File.SeekError
|| std.mem.Allocator.Error;
Zig can often infer error sets but only in some contexts today.
Our first Parser
All we need to do in order to implement a Parser is provide the _parse method, and define its return Value type and Reader input type:
const parser: Parser([]u8, @TypeOf(reader)) = .{
._parse = myParse,
};
In the above, the type T in const parser: T is denoting the type of the constant named parser - in this case it’ll be the type returned by Parser([]u8, @TypeOf(reader)). And this:
something = .{
._parse = myParse,
}
Is the Zig syntax for populating a struct. We’re setting the _parse field to myParse. Zig can infer the type of the struct if you write a .{} instead of T{} - which avoids the need for us to repeat the call to the Parser() function which is verbose.
What actually is a “Reader”?
Up to this point, we’ve just talked about Reader as being any type.
Similar to our Parser interface, the Zig standard library provides a std.io.Reader interface and there are many implementors of it including:
std.fs.Filestd.io.fixedBufferStream("foobar")std.net.Stream(network sockets)
However, in contrast to our Parser type which invokes function pointers at runtime, the std.io.Reader interface is a compile time type - meaning calls to the underlying implementation do not involve a pointer dereference.
Today, Zig is in early stages (version 0.7) and does not have anything like an interface or trait type (although it seems likely this will be improved in the future.)
This means that, for now, we cannot simply define our function as accepting only an std.io.Reader interface - instead we must declare that we accept any type which we’ll call Reader, write our code as if it is an std.io.Reader - and the compiler will just barf if anybody passes something in that isn’t an std.io.Reader. This can sometimes lead to confusing compiler error messages (“there’s an error in the standard library code? Ah, no, I just needed to pass a .reader()!").
A Parser that parses a literal string
If we want a Parser interface implementation that parses a specific string literal, one way to do that is to also make that a generic function which accepts any reader type (so we’re not restricted to e.g. just file inputs):
pub fn Literal(comptime Reader: type) type {
return struct {
// TODO
};
}
This is pretty good - but we need some way to have the type we return implement the Parser interface we defined. The way to do this is by defining a field in our struct:
pub fn Literal(comptime Reader: type) type {
return struct {
parser: Parser([]u8, Reader) = .{
._parse = parse,
},
};
}
Now a consumer can write the following to get a literal string parser:
const parser = Literal(@TypeOf(reader)).parser;
Passing parameters to a parser implementation
If we want our Literal parser to accept a parameter – the literal string to look for – we need to give it a parameter.
In the case of merely passing it a string, we could adjust the signature so that this is possible:
const parser = Literal("some string", @TypeOf(reader)).parser;
However, we’ll define ours using an init method which is more common in Zig data structures:
pub fn Literal(comptime Reader: type) type {
return struct {
parser: Parser([]u8, Reader) = .{
._parse = parse,
},
want: []const u8,
const Self = @This();
// The `want` string must stay alive for as long as the parser will be used.
pub fn init(want: []const u8) Self {
return Self{
.want = want
};
}
};
}
In this case, want is the string literal we want to match - and []const u8 is Zig’s string type. It describes a slice of immutable (non-modifiable) encoded UTF-8 bytes.
Unlike C, []const u8 being a slice means it is a pointer to the string in memory and its length - so we don’t have to pass around the length parameter separately or use a null-terminated string. In Zig, there are two ways to represent a string:
[]const u8(unmodifiable string, most common)[]u8(modifiable string)
Understanding Zig’s wild/confusing @fieldParentPtr
We’re finally ready to actually have our Literal parser parse something! We just need to implement our parse method:
pub fn Literal(comptime Reader: type) type {
return struct {
parser: Parser([]u8, Reader) = .{
._parse = parse,
},
want: []const u8,
...
const Self = @This();
fn parse(parser: *Parser([]u8, Reader), allocator: *Allocator, src: *Reader) callconv(.Inline) Error!?[]u8 {
const self = @fieldParentPtr(Self, "parser", parser);
...
}
};
}
But wait a minute! In order for the ._parse = parse, assignment to work the first argument to parse needs to be the self parameter for a Parser([]u8, Reader) - so how does our parse implementation method get to access the want field of our struct?
This is where some Zig magic comes in: on obscure builtin function we can use inside of our parse method:
const self = @fieldParentPtr(Self, "parser", parser);
To understand this, first let’s get a look at what these parameters are referring to:

We can see from the Zig documentation that this function operates as follows:
Given a pointer to a field, returns the base pointer of a struct.
So in our case:
Selfis the “parent struct” we’re trying to acquire a reference to (our type)"parser"is the name of our struct’s field.parseris the pointer to ourparserstruct field.
Hopefully you can start to see the link here: parser is a pointer to our struct field, so Zig has a little helper @fieldParentPtr which can rely on that fact to give us our struct given a pointer to our struct field.
Implementing the rest of parse
Our full parse method will look like this:
// If a value is returned, it is up to the caller to free it.
fn parse(parser: *Parser([]u8, Reader), allocator: *Allocator, src: *Reader) callconv(.Inline) Error!?[]u8 {
const self = @fieldParentPtr(Self, "parser", parser);
const buf = try allocator.alloc(u8, self.want.len);
errdefer allocator.free(buf);
const read = try src.reader().readAll(buf);
if (read < self.want.len or !std.mem.eql(u8, buf, self.want)) {
try src.seekableStream().seekBy(-@intCast(i64, read));
allocator.free(buf); // parsing failed
return null;
}
return buf;
}
There are a few notable things here:
- We’re trying to return a string from our
parsefunction, i.e. the value it emits is a string (instead of an AST node). - The
wantstring we got inside of ourinitmethod is agreed to only be valid whileparsewill still be called. We’ve decided to create a contract that all of ourParserimplementations will either not hold onto memory given by others - or if they do, only do so untilparsereturns. Hence, we need to allocate a new string in our method. - Normally we could rely solely on
defer(“run at end of function”) orerrdefer(“run if an error is returned”), but since we’ve chosen to reserve the none optionalnullas “we didn’t parse anything” we need to manually free if wereturn null;. Anulldeferandsomedefercould be nice, maybe?
Putting it all together, you’ll get something like this: GitHub gist.
Our first parser combinator
To demonstrate how a parser combinator would be implemented, we’ll try implementing the OneOf operator. It will take any number of parsers as input and run them consecutively until one succeeds or none do.
Let’s first start by writing out the basic structure of our function:
pub fn OneOf(comptime Value: type, comptime Reader: type) type {
return struct {
parser: Parser(Value, Reader) = .{
._parse = parse,
},
...
};
}
You’ll notice here that in contrast to our Literal parser function from earlier, this function takes a second comptime Value: type parameter. This is because we want it to work with any existing Parser implementation, regardless of what type of value it produces.
We can start to fill in the type by adding our init method:
pub fn OneOf(comptime Value: type, comptime Reader: type) type {
return struct {
parser: Parser(Value, Reader) = .{
._parse = parse,
},
parsers: []*Parser(Value, Reader),
const Self = @This();
// `parsers` slice must stay alive for as long as the parser will be
// used.
pub fn init(parsers: []*Parser(Value, Reader)) Self {
return Self{
.parsers = parsers,
};
}
};
}
As you can see here, we’re going to simply take in a list of pointers to parsers. They’ll all need to have the same return Value as was specified in the call to OneOf.
One reason for this is that Zig does not support return type inference. You can have a function which takes anytype as a parameter, but it cannot return an anytype. This just means we need to have a generic function (in this case, OneOf) which accepts a type parameter and then use that Value type later. In a language like Haskell or OCaml, this would not be true.
Finally, we can implement our parse method:
pub fn OneOf(comptime Value: type, comptime Reader: type) type {
return struct {
...
// Caller is responsible for freeing the value, if any.
fn parse(parser: *Parser(Value, Reader), allocator: *Allocator, src: *Reader) callconv(.Inline) Error!?Value {
const self = @fieldParentPtr(Self, "parser", parser);
for (self.parsers) | one_of_parser | {
const result = try one_of_parser.parse(allocator, src);
if (result != null) {
return result;
}
}
return null;
}
};
}
There are a few things to unpack here:
try one_of_parser.parse(allocator, src);indicates that if parsing usingone_of_parserreturns an error that our function should return immediately and not continue attempting to parse with other parsers.if (result != null) {is how you check if an Optional type in Zig is “None”. I find this pretty interesting: it’s notnull, it’s actually an optional “none” type - but it is callednull. I’m not sure why, but can imagine this making the language friendlier to people unfamiliar with optional types.
Using our OneOf parser combinator
Now for the cool part: we get to put both our Literal parser and OneOf parser combinator to build a new parser!
// Define our parser.
var one_of = OneOf([]u8, @TypeOf(reader)).init(&.{
&Literal(@TypeOf(reader)).init("dog").parser,
&Literal(@TypeOf(reader)).init("sheep").parser,
&Literal(@TypeOf(reader)).init("cat").parser,
});
The above will parse one of "dog", "sheep", or "cat" from the input reader.
We’re passing @TypeOf(reader) frequently above which makes the code a bit more cryptic than needed, and it would be possible to introduce a OneOfLiteral helper which makes the above instead read:
// Define our parser.
var one_of = OneOfLiteral([]u8, @TypeOf(reader)).init(&.{
"dog",
"cat",
"sheep",
});
One thing to unpack here is this syntax for passing an array to init: &.{...}:
- The function takes a parameter
parsers: []*Parser(Value, Reader) .{...}would give us a fixed size array[3]*Parser(Value, Reader)&.{}gives us a pointer to an array, i.e. a slice[]*Parser(Value, Reader).
Since our list is known at compile time, we don’t have to allocate or free memory for the slice. If our list was dynamic, we would need to do so.
Finally, we can actually use our parser above:
var p = &one_of.parser;
var result = try p.parse(allocator, &reader);
std.testing.expectEqualStrings("cat", result.?);
if (result) |r| {
allocator.free(r);
}
Runtime parser generation
You might be wondering how we would go from the Literal parser and OneOf parser combinator to actually generating a parser at runtime that can parse the semantics defined in a regexp string.
Since our Parser interface is a runtime interface (you can swap out the implementation at runtime) and since our parser combinator OneOf operates using that interface (only the return value must be known at compile time, it could be a generic AST node) it means that we can easily dynamically create slices of []*Parser(...) at runtime based on the result of a parser combinator we have built - like our “dog, cat, sheep” parser from earlier.
The challenge left for you as a reader is to:
- Write parsers like our
Literalparser that can parse the components of our regexpa[bc].*abc:RegexLiteralParsercan parsea,b, andc, but notabc(the string.)RegexRangeOpenParsercan parse[.RegexRangeCloseParsercan parse]RegexAnyParsercan parse the.“any character” syntax.RegexRepetitionParsercan parse the*repetition operator.
- Write a parser combinators like our
OneOfparser, except have it parse aSequenceof parsers. - Use our
Sequenceparser combinator andRegexLiteralParserto build aRegexStringLiteralParser- similar to how we built out “dog, cat, sheep” parser. - Write a new kind of function called a runtime parser generator named
RegexParserwhich will be super familiar:- Take in a parser combinator called
RegexSyntaxParserwhich can turn your regexp syntax into some intermediary like an AST. - Have your function use parser combinators like OneOf, Sequence, etc. to build a brand new parser at runtime based on that intermediary AST.
- Return that new parser which parses the actual semantics described by the input regexp!
- Take in a parser combinator called
Closing thoughts
I am sorry for not giving you a full (or even partial) regex engine :) I am still exploring this and it is a large undertaking, this blog post would be far too long if it was included.
You can find a copy of the final code with parsers and parser combinators here. Just zig init-exe and plop them into your src/ directory.
You may also want to check out Mecha, a parser combinator library for Zig.
If anything was unclear or confusing, I’m happy to help: shoot me an email [email protected] or leave a comment on Hacker News / Reddit and I’ll follow up.