Let's build an Entity Component System from scratch (part 1)
In this multi-part series we’ll build the Entity Component System used in Mach engine in the Zig programming language from first principles (asking what an ECS is and walking through what problems it solves) all the way to writing an implementation in a low-level programming language. The only thing you need to follow along is some programming experience and a desire to learn.
In this article, we’ll mostly go over the problem space, data oriented design, the things we need our ECS to solve, etc. In the next article, implementation will begin.
- Motivation
- My approach to complex software architecture
- What really is an entity component system, anyway?
- What problems does an ECS solve?
- Start with data oriented design
- What would data oriented design look like? (code starts here!)
- Sparse data storage
- Archetype storage
- Designing our ECS
- Next up: starting our ECS implementation
Motivation

I’ve used and written more traditional OOP scene graphs in the past. These are often the core engine architecture used to represent everything in game worlds: they’re used in Unity historically (which is now migrating to ECS due to popular demand) and even in other modern engines such as Godot.
For Mach engine, however, we’re adopting an ECS as our core architecture. ECS has gained great momentum in recent years for its composition and performance benefits.
My approach to complex software architecture
- What user problems does the proposed architecture (scene graphs, ECS, React-like frameworks, etc.) solve?
- How does the proposed architecture typically solve such problems?
The key point here is that, personally, I find it useful to intentionally avoid looking directly at code for the implementations themselves.

I’ve used this approach to to great success before: the nice thing about this is that the end result really fits the language, using patterns and features specific to the language - it doesn’t just end up feeling like a port of some other language’s implementation.
I’ve researched a bit about ECS in general, and have chatted with people familiar with ECS, but haven’t read any other’s code. No doubt, initially, I’ll get some aspects wrong! As this series of articles progresses over the coming months, though, you’ll see how this can be a winning tactic as we learn together!
What really is an entity component system, anyway?

I’ve found the Rust project Bevy ECS to have a great succinct explanation, which I further simplify here:
- Entities: a unique integer
- Components: structs of plain old data
- Systems: normal functions
When you hear this, things may start to sounds a whole lot simpler! Those are the core concepts of an ECS.
There is one other concept of an ECS that I think is particularly important:
- Archetype: A chosen set of components that an entity of a certain type will have.

What problems does an ECS solve?
I’ve identified two problems it solves.

First and foremost is making it easy for game developers to architect their code compared to them doing it manually. If it’s easier for someone to structure their code themselves, manually, then such a system is not useful at all! Of course, as complexity and the scale of software increases then a consistent system is far more useful than a bunch of ad-hoc systems.
The second problem ECS solves, I believe, is making your software architecture efficient without you really having to think too much about it. You don’t have to think about how to structure all your code & data for logic first, and then for performance, but rather get good performance by nature of following patterns.
Start with data oriented design
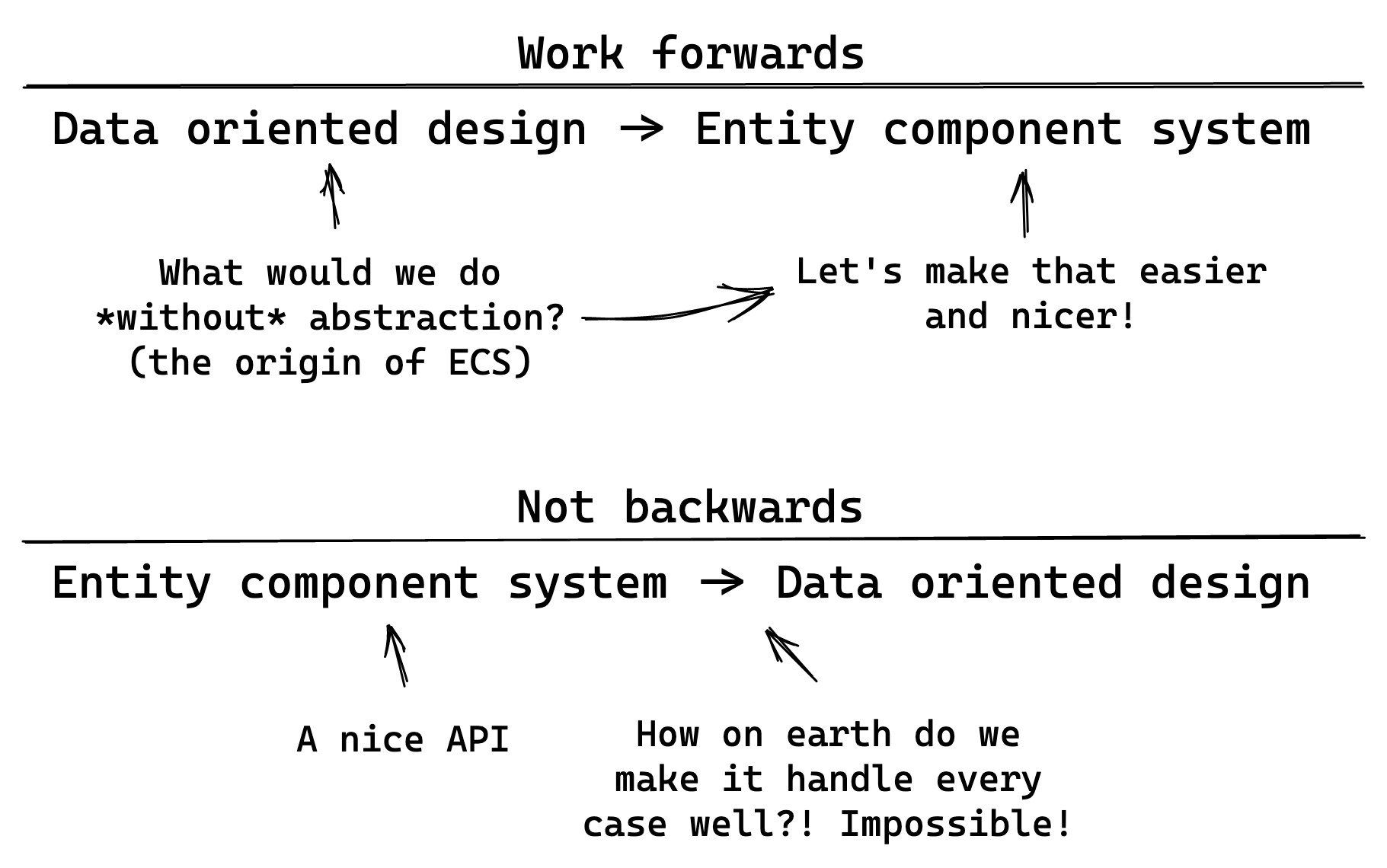
ECS overlaps with data oriented design in many ways (although it’s roots are much earlier). There are many talks about data oriented design including Mike Acton’s at CppCon, and my personal favorite “A Practical Guide to Applying Data-Oriented Design” by Andrew Kelley. You don’t have to watch either, I’ll cover the important concepts we use here. But I highly suggest every developer watch Andrew Kelley’s talk above. It’s eye opening no matter what kind of programming you are doing.
Let’s work forwards, not backwards: We’re not starting by building an ECS, we’re starting by building a proper data oriented design for CPU cache and memory efficiency, and then we’re working towards “how do we make that easier for people to do by default?” and looking to existing ECS architectures for inspiration.
What would data oriented design look like? (code starts here!)
A simple first approach would be something like this:
const Player = struct {
name: []const u8, // a string / byte slice
location: Vec3,
velocity: Vec3,
health: u8,
team: Team,
alive: bool,
};
const Cat = struct {
name: []const u8, // a string / byte slice
location: Vec3,
};
const Monster = struct {
location: Vec3,
health: u8,
};
// All the players, cats, monsters in our game world.
var players: ArrayList(Player) = .{};
var cats: ArrayList(Cat) = .{};
var monsters: ArrayList(Monster) = .{};
// The index of a player in the players array, a cat in the cats array, etc.!
const Entity = u32;
Now we can refer to players, cats, or monsters by using an entity ID (their index in the array), which we call an entity. We could also write functions (called systems) which iterate over these arrays and e.g. compute physics for players.
However, we can improve this quite a bit!
Sparse data storage
Comptime sparse data
It’s likely that most players will be alive in our game, only a few will be dead at a time - but yet we’re paying the cost of storing which players are dead for every living player (via the Player.alive struct field)!
We can eliminate paying the cost of alive: bool per player by removing the field entirely, and having what I call compile time sparse data instead:
var alive_players: ArrayList(Player) = .{};
var dead_players: ArrayList(Player) = .{};
This not only reduces the amount of memory each Player entity takes up because we no longer store an alive: bool per player, but also it:
- Improves performance by ensuring more players fit into L1/L2/L3 cache.
- Reduces the amount of players we must skip (and reduces potential cache misses) because in some cases we might only be interested in alive players and have to skip over dead ones when iterating.
This introduces some complexity for us to deal with, though:
- Now if a player goes from dead->alive, or alive->dead, we need logic to remove it from the old array and put it in the new one.
- When we move a player from one array to another, the Entity ID we use to refer to that player (the array index) has changed! So if someone is storing a player Entity ID in order to have reference to it somewhere, we’d need to have logic to update that.
Now we start to see one thing our ECS needs to make simpler!
I call this type of data comptime sparse data.
Runtime sparse data
In an ideal world, we’re able to pre-declare all sparse data at compile time like we did above:
var alive_players: ArrayList(Player) = .{};
var dead_players: ArrayList(Player) = .{};
But sometimes, this just isn’t possible:
- Maybe players in your game can give other players a customer nickname to display above their head. Again, for most players this won’t be set - but for some players it will be! Ideally we don’t have to pay the cost of storing a nickname string pointer for every player in the game without one
- Maybe a handful of players out of thousands are given the speciality of having a custom weapon, they get to choose it’s type, a custom name for it, and even the damage it should do! Where should we store that information?
- …
In this case, we could use a hash map:
const PlayerNickname = []const u8; // a string
const Weapon = struct {
custom_name: []const u8, // a string
type: WeaponType,
damage: u8,
};
var players: ArrayList(Player) = .{}; // all players
var players_with_nicknames = AutoHashMap(Entity, PlayerNickname).init(allocator);
var players_with_weapons = AutoHashMap(Entity, Weapon).init(allocator);
Now we’ve got a mapping of player Entity IDs -> their nicknames and weapons. We only pay the cost of storing this information for players that do actually have these specialties - not for every player.
I call this type of data runtime sparse data.
Improving performance
Consider our player storage as it stands right now:
const Player = struct {
name: []const u8, // a string / byte slice
location: Vec3,
velocity: Vec3,
health: u8,
team: Team,
};
var players: ArrayList(Player) = .{}; // all players
Because of the way structs get laid out in memory with padding, our players array above would end up having a larger memory footprint than needed. So we actually benefit from using a separate array for every type of data (thanks, Unity!):
var player_names: ArrayList([]const u8) = .{};
var player_locations: ArrayList(Vec3) = .{};
var player_velocities: ArrayList(Vec3) = .{};
var player_healths: ArrayList(u8) = .{};
var player_teams: ArrayList(Team) = .{};
Luckily, we don’t actually have to enumerate all our fields out like this: Zig has a nice MultiArrayList type which does this for us, we need change only one line:
const Player = struct {
name: []const u8, // a string / byte slice
location: Vec3,
velocity: Vec3,
health: u8,
team: Team,
};
-var players: ArrayList(Player) = .{}; // all players
+var players: MultiArrayList(Player) = .{}; // all players
Not only does this use less memory, it also improves CPU cache efficiency a ton, especially when iterating over a lot of players to do work with them. If you’re curious why, then you should watch Andrew Kelley’s “A Practical Guide to Applying Data-Oriented Design” talk!
Archetype storage
Comptime archetype storage
Up until now, we’ve assumed we have pre-defined archetypes (“player”, “cat”, “monster”):
// All the players, cats, monsters in our game world.
var players: ArrayList(Player) = .{};
var cats: ArrayList(Cat) = .{};
var monsters: ArrayList(Monster) = .{};
This is ideal: we don’t need to ask the computer to do any work to find out where players, cats, or monsters are stored - we just know at compile time because they’re in that variable. When someone uses our ECS, we could have them write a compile time function like:
World(.{
Player,
Cat,
Monster,
})
And that’s great because it means our ECS “world” can be aware ahead of time exactly which archetypes it needs to store. It could write out those var players: ArrayList... variables for us.
I call this comptime archetype storage.
Runtime archetype storage
However, real games are much more complex: we might not really know at the time we’re declaring the World all the different archetypes we plan on storing. Code gets messy. In some cases, maybe we even need to define some archetypes of a common type at runtime. For example, if we wanted to allow configuring red and blue here (or the number of teams) via a configuration file on disk or via a GUI:
var red_team_players: ArrayList(Player) = .{};
var blue_team_players: ArrayList(Player) = .{};
Of course our Player could have a team field in it to represent the team, but there may be cases where storing a separate list of entities like this is needed without pre-declaring it. If we want to do that, we could use a hashmap:
var runtime_archetypes = AutoHashMap([]const u8, *anyopaque).init(allocator);
In this model, we could store the archtype string name as the hashmap key (for example, the @typeName(Player) if we wanted, or maybe a custom name like red, blue, etc.). The value of the hashmap would need to be different types: an ArrayList(Player), an ArrayList(Monster), etc. and so we would store a type-erased *anyopaque (like a C void*) pointer. When we get a value out, we’ll need to “know” what type of ArrayList to cast the pointer back to. It won’t store that info for us.
I call this runtime archetype storage.
Designing our ECS
We now start to see some of the things our ECS architecture should solve:
- Typed entity storage (how you interact with a list of players, monsters, etc.)
- Sparse data: both comptime and runtime
- Archetype storage: both comptime and runtime
Additionally, these are the design principles I’ve come up with:
- Clean-room implementation (I’ve not read any other ECS implementation code), just working from first-principles as an engineer
- Solve the problems ECS solves, in a way that is natural to Zig and leverages Zig comptime.
- Fast. Optimal for CPU caches, multi-threaded, leverage comptime as much as is reasonable.
- Simple. Small API footprint, should be natural and fun - not like you’re writing boilerplate.
- Enable other libraries to provide tracing, editors, visualizers, profilers, etc.
From this, you can easily gather that storing entities is actually only a small (but critical) portion of this system. In the next article we will get into the details of implementing this in code, and go on to explore more challenging topics like multi-threading, systems, and scheduling in future articles.
Next up: starting our ECS implementation
As this series develops, all the code is being developed in the Mach repository’s ecs subfolder on GitHub. The articles will lag slightly behind.
As more articles come out, you can find them here. Join us in developing it, give us advice, etc. on Matrix chat or follow updates on Twitter.
If you like what I’m doing, you can sponsor me on GitHub.